Introduction
In previous tutorial, we’ve looked at utilities for linking processes together and monitoring their lifecycle as it changes. The ability to link and monitor are foundational tools for building reliable systems and are the bedrock principles on which Cloud Haskell’s supervision capabilities are built.
A Supervisor manages a set of child processes throughout their entire lifecycle,
from birth (spawning) till death (exiting). Supervision is a key component in building
fault tolerant systems, providing applications with a structured way to recover from
isolated failures without the whole system crashing. Supervisors allow us to structure
our applications as independently managed subsystems, each with its own dependencies
(and inter-dependencies with other subsystems) and specify various policies determining
the fashion in which these subsystems are to be started, stopped (i.e., terminated)
and how they should behave at each level in case of failures.
Supervisors also provide a convenient means to shut down a system (or subsystem) in a controlled fashion, since supervisors will always terminate their children before exiting themselves and do so based on the policies supplied when they were initially created.
Quis custodiet ipsos custodes
Supervisors can be used to construct a tree of processes, where some children are workers (e.g., regular processes) and others are themselves supervisors. Each supervisor is responsible for monitoring its children and handling child failures by policy, as well as deliberately terminating children when instructed to do so (either explicitly per child, or when the supervisor is itself told to terminate).
Each supervisor takes with a list of child specifications, which tell the supervisor how to interact with its children. Each specification provides the supervisor with the following information about the corresponding child process:
ChildKey: used to identify the child specification and process (once it has started)ChildType: indicates whether the child is a worker or another (nested) supervisorRestartPolicy: tells the supervisor under what circumstances the child should be restartedChildTerminationPolicy: tells the supervisor how to terminate the child, should it need toChildStart: provides a means for the supervisor to start/spawn the child process
The RestartPolicy determines the circumstances under which a child should be
restarted when the supervisor detects that it has exited. A Permanent child will
always be restarted, whilst a Temporary child is never restarted. Transient children
are only restarted if the exit normally (i.e., the DiedReason the supervisor sees for
the child is DiedNormal rather than DiedException). Intrinsic children behave
exactly like Transient ones, except that if they terminate normally, the whole
supervisor (i.e., all the other children) exits normally as well, as if someone had
triggered the shutdown/terminate sequence for the supervisor’s process explicitly.
When a supervisor is told directly to terminate a child process, it uses the
ChildTerminationPolicy to determine whether the child should be terminated
gracefully or brutally killed. This shutdown protocol is used throughout
distributed-process-supervisor and in order for a child process to be managed
effectively by its supervisor, it is imperative that it understands the protocol.
When a graceful shutdown is required, the supervisor will send an exit signal to the
child process, with the ExitReason set to ExitShutdown, whence the child process is
expected to perform any required cleanup and then exit with the same ExitReason,
indicating that the shutdown happened cleanly/gracefully. On the other hand, when
the RestartPolicy is set to TerminateImmediately, the supervisor will not send
an exit signal at all, calling the kill primitive instead of the exit primitive.
This immediately kills the child process without giving it the opportunity to clean
up its internal state at all. The gracefull shutdown mode, TerminateTimeout, must
provide a timeout value. The supervisor attempts a gracefull shutdown initially,
however if the child does not exit within the given time window, the supervisor will
automatically revert to a brutal kill using TerminateImmediately. If the
timeout value is set to Infinity, the supervisor will wait indefintiely for the
child to exit cleanly.
When a supervisor detects a child exit, it will attempt a restart. Whilst explicitly
terminating a child will only terminate the specified child process, unexpected
child exits can trigger a branch restart, where other (sibling) child processes are
restarted along with the child that failed. How the supervisor goes about this
branch restart is governed by the RestartStrategy given when the supervisor is
first started.
Whenever a
RestartStrategycauses multiple children to be restarted in response to a single child failure, a branch restart incorporating some (possibly a subset) of the supervisor’s remaining children will be triggered. The exceptions to this rule areTemporarychildren andTransientchildren that exit normally, therefore not triggering a restart. The basic rule of thumb is that, if a child should be restarted and theRestartStrategyis notRestartOne, then a branch containing some other children will be restarted as well. ——
Isolated Restarts
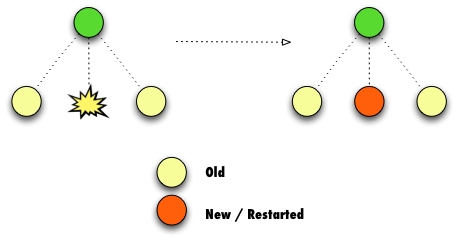
The RestartOne strategy is very simple. When one child fails, only that individual
child is restarted and its siblings are left running. Use RestartOne whenever the
processes being supervised are completely independent of one another, or a child can
be restarted and lose it’s state without adversely affecting its siblings.
 ——-
——-
All or nothing restarts
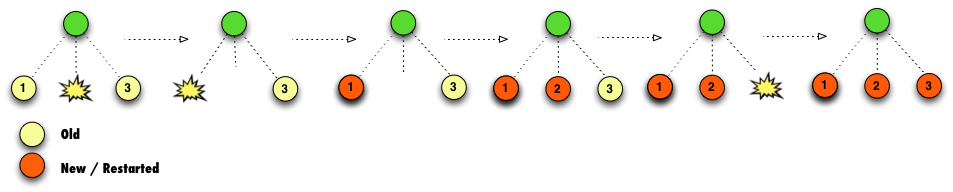
The RestartAll strategy is used when our children are all inter-dependent and it’s
necessary to restart them all whenever one child crashes. This strategy triggers one of
those branch restarts we mentioned earlier, which in this case means that all the
supervisor’s children are restarted if any child fails.
The order and manner in which the surviving children are restarted depends on the chosen
RestartMode which parameterises the RestartStrategy. This comes in three flavours:
RestartEach: stops then starts each child sequentiallyRestartInOrder: stops all children first (in order), then restarts them sequentiallyRestartRevOrder: stops all children in one order, then restarts them sequentially in the opposite
Each RestartMode is further parameterised by its RestartOrder, which is either left
to righ, or right to left. To illustrate, we will consider three alternative configurations
here, starting with RestartEach and LeftToRight.
 ——-
——-
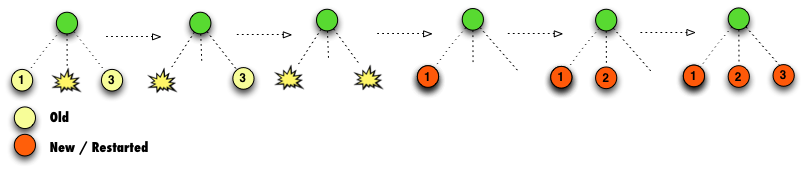
There are times when we need to shut down all the children first, before restarting them.
The RestartInOrder mode will do this, shutting the children down according to our chosen
RestartOrder and then starting them up in the same way. Here’s an example demonstrating
RestartInOrder using LeftToRight.
 ——-
——-
If we’d chosen RightToLeft, the children would have been stopped from right to left (i.e.,
starting with child-3, then child-2, etc) and then restarted in the same order.
The astute reader might’ve noticed that so far, we’ve yet to demonstrate the behaviour that’s default in Erlang/OTP’s Supervisor, and it’s a default for good reason. It is not uncommon for children to depend on one another and therefore need to be started in the correct order. Since these children rely on their siblings to function, we must stop them in the opposite order, otherwise the dependent children might crash whilst we’re restarting other processes they rely on. It follows that, in this setup, we cannot subsequently (re)start the children in the same order we stopped them either.